





基于NXP ARM 微控制器的以太網吞吐性能
1.簡介
以太網是世界上應用最廣泛的局域網技術。以太網從1980年代起就開始應用,已有IEEE 802.3標準,規定了一系列傳輸速率。在嵌入式系統中,應用最普遍的是10Mbit/s和100Mbit/s(就是通常所說的10/100以太網)。
現在NXP(恩智浦半導體)有超過20款內置以太網功能的ARM MCU,覆蓋了3代ARM架構(ARM7,ARM9,Cortex-M3)。NXP在3種架構中采用了相同的實現方法,所以在系統更新換代時,設計人員可以節省大量的時間和資源。
1.1 優異的實現方法
NXP的以太網部件(見圖1)包含一個全功能10/100 MAC(媒體訪問控制器),使用DMA硬件加速以提高性能。MAC完全符合IEEE 802.3標準,并使用MII(媒體獨立接口)或RMII(精簡MII)協議,通過片上MIIM(媒體獨立接口管理)總線,與片外以太網PHY(physical layer 物理層)連接。
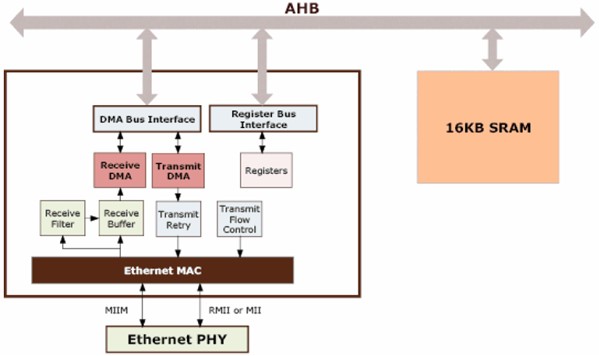
圖1 LPC24xx以太網部件
NXP以太網的優異性能如下所述:
(1) 全以太網功能
該部件支持以太網的所有操作,符合802.3標準。
(2) 增強型架構
NXP提高了架構的性能,增加了幾個額外的功能,包括接收過濾、自動抵觸返回(collision back-off)、幀重發、電源管理(通過部件選擇)等等。
(3) DMA硬件加速
該部件有兩個DMA管理器,分別負責發送和接收。使用分散收集DMA(Scatter-Gather DMA)自動幀重發和接收,進一步卸載CPU(offloads the CPU)。
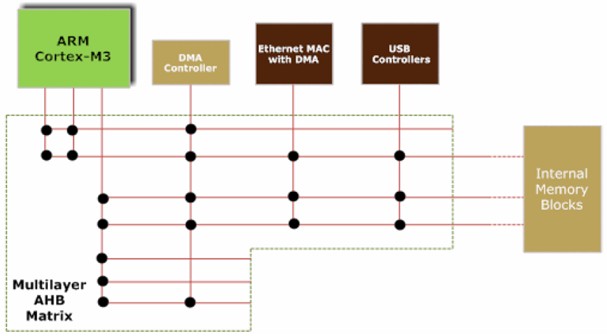
圖2 NXP Cortex-M3 架構
2.NXP LPC1700微控制器的以太網吞吐性能
在以太網中,兩個或更多站使用以太網協議通過公用通道發送或接收數據。對每一個網絡要素(通道或站),以太網性能有不同的含義。帶寬、吞吐量、延遲是衡量整體性能的重要指標。對于通道,用帶寬來衡量連接性能,而吞吐量則代表可用數據在通道中發送的速率。對于站,以太網性能意味著設備在以太網通道中全速操作的能力。另一方面,延遲用于衡量幾種因素(傳送時間、處理時間、故障、重試等等)引起的遲滯時間。
本文檔的著重點放在NXP LPC1700操作全速以太網通道的性能(通過以太網接口,由內部EMAC模塊和外部PHY芯片提供)。在這種方式下,吞吐量定義為MCU每秒發送到通道或從通道接收的可用數據。這個概念適用于其他支持以太網的NXP LPC微控制器。不幸的是,這些測試通常都需要特定的設備,如網絡分析器和/或網絡通信發生器,以獲得精確的測量結果。不過,使用簡單的測試步驟獲得估計值是可以做到的。實際上,我們的目的是搞明白影響以太網吞吐性能的不同因素,所以用戶可以關注不同的技術,以改進以太網的性能。
這里,我們只考慮發送器的吞吐性能;而接收器會有一點復雜,因為它涉及到發送器發送信息到通道的性能(這種情況下,接收器的吞吐量受到發送器通道發送信息的吞吐量的影響)。我們只要得到發送器的吞吐數據,我們就能把這個數據當作接收器可以達到的最大理想數據(在理想條件下),就能獲得與接收器的吞吐數據。
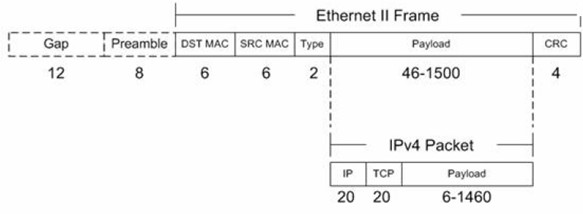
圖3 以太網II格式
考慮100Mbit/s 1位的速率,每一幀(frame)包含負載(可用數據,最小46B,最大1500B),以太網的頭部(14B),CRC(4B),序文(Preamble,8B),內部包缺口(inter-Packet Gap,12B),以下為每秒最大可能幀和吞吐量;
最小幀:(46B的數據)->1448809幀/秒->6.84MB/s
最大幀:(1500B的數據)->8127幀/秒->12.19MB/s
以上的速率是實際中可能達到的最大可能值。這些值是理想情況下的值,實際中會比這小。
注意:(1)幀/s是通過以太網連接速度(100M bit/s)除以總的幀位大小計算得到的(最小幀:84*8=672,最大幀:1538*8=12304)。
(2)MB/s是通過幀/s乘以每一幀可用數據的字節數得到的(最小幀:46B,最大幀:1500B)。
2.1 測試條件
- MCU:LPC1768,100MHz
- Board:Keil MCB 1700
- PHY chip:National DP83848(RMII 接口)
- 工具鏈:Keil uVision4 v4.1
- 從RAM運行代碼
- TxDescriptorNumber=3
- 以太網模式:全雙工-100Mbit/s
2.2 測試描述
為了得到最大吞吐量,將發送由1514B(包含以太網頭部)、75B負載(可用數據)組成的50個幀。EMAC控制器(以太網控制器)將自動添加上CRC(4B)。為了測量這個處理過程所花費的時間,一個GPIO(本例為P0.0)在發送幀時置位,發送完畢后立即清零。可以用示波器測量P0.0引腳上產生脈沖的寬度,這樣就能得到相應的時間。板子通過以太網電纜連接到PC上。
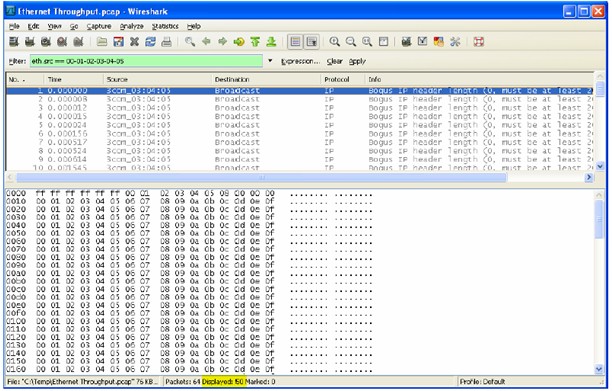
圖4 用WireShark檢查數據
PC上運行一個嗅探器程序(本例中為WireShark http://www.wireshark.org/ )來檢查50個幀是否發送、數據是否正確。負載中有一個特殊的部分,一旦發生錯誤,就可以識別。50個幀到達PC時無錯,則測試有效。
2.3 測試
EMAC使用系列符號,提供了相應的指針以指示數據緩沖、控制和狀態信息的存儲位置。傳送時,幀數據在進入數據緩沖器時被應用代替。EMAC使用DMA獲得用戶數據,并在發出之前裝載幀負載。
如上所述,應用程序所使用的以復制數據到數據緩沖器的方法,將會影響吞吐量的測量。有三種情況:
- (1)理想情況下,完全不考慮應用程序。
- (2)典型情況,應用程序使用處理器復制數據到EMAC數據緩沖器。
- (3)優化情況下,應用程序通過DMA復制數據到EMAC數據緩沖器。
2.3.1 情況描述
1.理想情況:在這種情況下,軟件用測試部件建立符號數據緩沖器,且只有TxProduceIndex增長50倍,觸發幀的發送。換句話說,根本無需考慮應用,即使不是典型的用戶情況,仍然可以在發送時提供最大的可能吞吐。
2.典型情況:這種情況比較典型,在發送幀之前應用程序復制數據到符號數據緩沖器。與之前的結果相比,可以明顯看到應用程序影響到整體性能。此種情況,不宜作為實際EMAC的吞吐量。然而,這個例子說明了未優化的應用程序如何降低整體性能,給人的印像就是硬件太慢了。
3.優化情況:使用DMA,復制應用數據到符號數據緩沖器。這種情況下,采用優化的方法,體現出快速LPC1700的優點。
2.4 軟件
本文檔中,提供了Keil MDK工程形式的測試軟件方案。
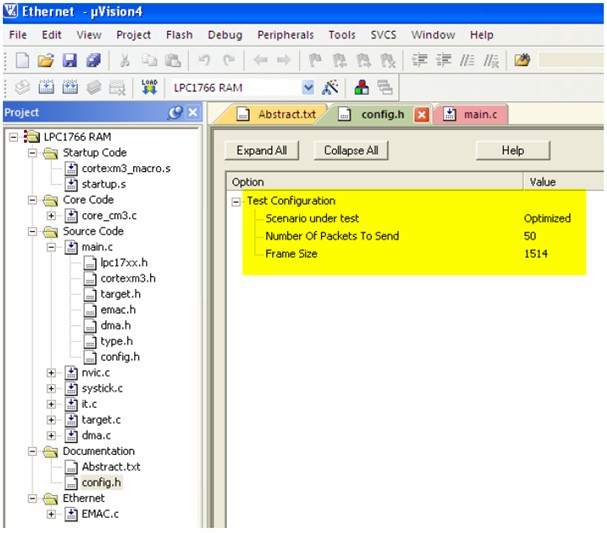
打開config.h文件,使用配置向導,可以選擇想要的模式。除此之外,發送包的數量和幀的大小也可以在此文件中修改。
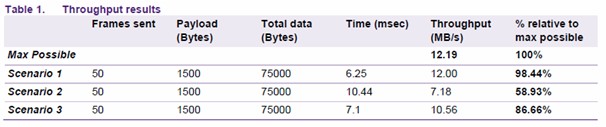
2.5 測試結果
測試結果做成表格如下所示:
3.結論
盡管情況1不符合實際,但它提供的最大可能值可以作為參考,它非常接近以太網100Mbit/s的最大可能值。情況2,很明顯影響到整體性能。最后,情況3,通過優化可以改進整體的吞吐量。
從FLASH運行代碼(而不是從arm)也可以進行優化,且能得到更好的結果。
總之,以太網的吞吐量主要受傳輸數據到符號數據緩沖器的方式的影響。改進此過程,可以大大提高以太網的整體性能。LPC1700以及其他LPC系統的芯片都可以進行優化(基于DMA的支持、EMAC硬件和智能存儲總線架構)。
全文PDF文檔下載:
